Как быстро найти устаревший контент на сайте с помощью Screaming Frog
Сегодняшняя статья в первую очередь будет полезна тем, у кого на сайте есть обширный статейный раздел, владельцам новостных порталов и блогов. Я хочу рассказать о том, как быстро собрать данные о возрасте страниц с помощью кастомной настройки парсера Screaming Frog.
Также поговорим о том, как обновлять контент правильно, чтобы это сказалось на позициях документа.





Зачем это нужно
Один из главных приоритетов поисковиков - актуальность информации. Если ваша статья, гайд или рейтинг не обновлялись несколько лет, то вы рано или поздно заметите просадку трафика и позиций по соответствующим позициям. Даже если содержимое останется актуальным. К сожалению, в SEO-продвижении в принципе нет понятия “сделал и забыл”, и сам процесс во многом напоминает бесконечный бег в колесе.
Когда-то давно, по неопытности мне казалось, что покинуть колесо можно выбирая в качестве тем только так называемые evergreen топики, но и это далеко не так. Да, вечнозелёные темы держатся в выдаче стабильнее, поскольку, условно говоря, маловероятно, что в биографии Джона Леннона что-то вдруг изменится. Но и они просядут рано или поздно. Выйдет новая документалка, найдут архивную запись, Йоко Оно даст интервью… Ваш конкурент впишет параграф в свою статью и наберёт больше “очков” релевантности в глазах ПС, а вы нет. Поэтому также хочу отметить важный момент: всё течёт и изменяется, а вечнозелёный контент не существует.
Как искать старые страницы на сайте
Если у вас ламповый блог на сто страниц, то всё просто. Но что делать тем у кого древний городской портал с тысячами новостей и заметок? Итак нам понадобятся:
- Парсер Screaming Frog (подойдёт только активированная лицензия)
- 10 минут свободного времени
- Гугл таблицы для дальнейшей работы (опционально)
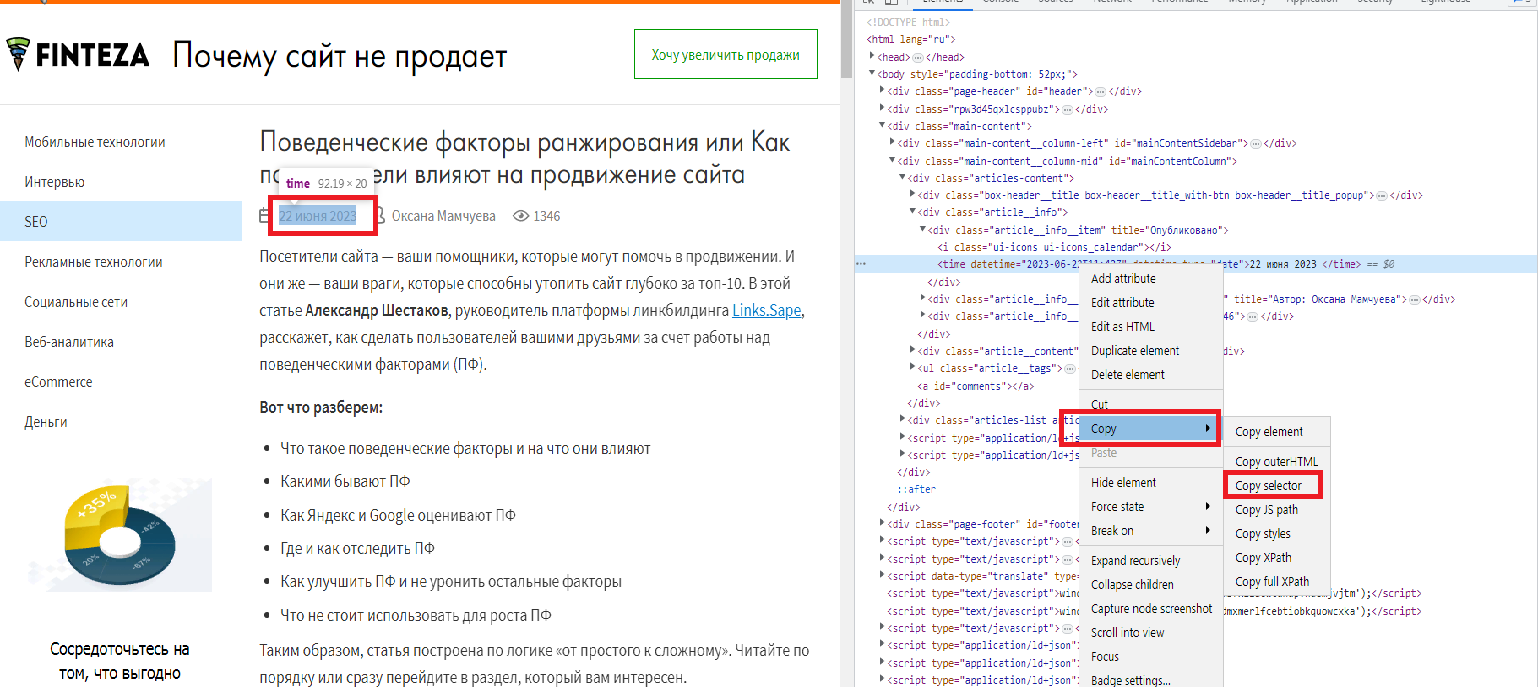
Итак, находим дату публикации и кликаем на неё правой кнопкой мыши → исследовать элемент.

У нас открывается панель с инструментами разработчика, и в свою очередь там на соответствующей строке кликаем пкм и в подменю copy выбираем copy selector.
Далее запускаем лягушку и во вкладке configuration переходим в меню custom → extraction.
Данный функционал недоступен в бесплатной версии программы, именно поэтому я вначале сказал, что вам потребуется полная лицензия.
Задаём название колонки (в моём примере date), в выпадающем меню выбираем CSSpath, далее вставляем скопированный ранее селектор и на следующем шаге выбираем extract text.
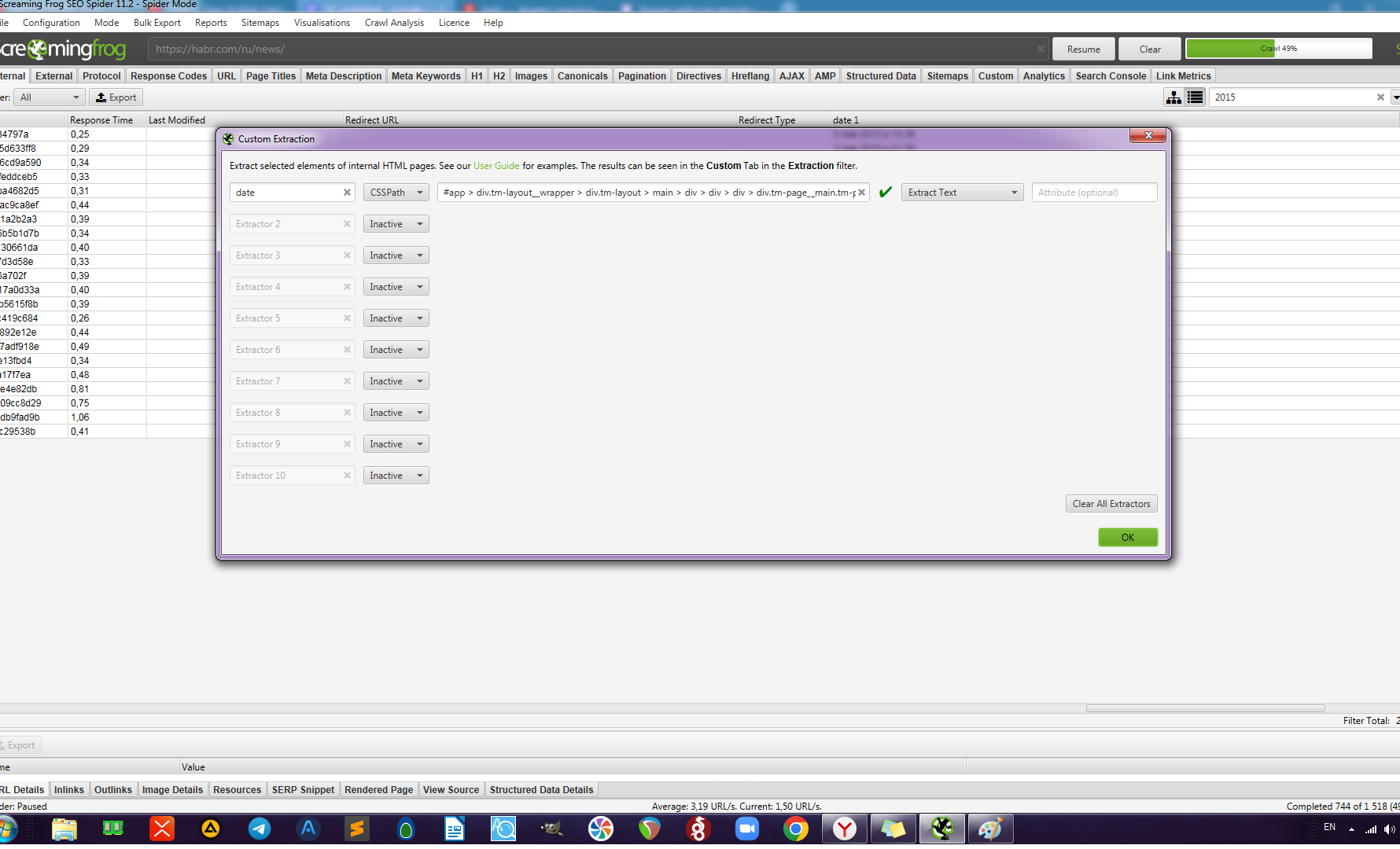
В принципе, уже здесь можно начинать парсинг. Но в случае, если у вас огромный сайт, скажем несколько тысяч страниц подшипников, а вам нужно просканировать только определённые разделы, то можно сузить диапазон парсинга.
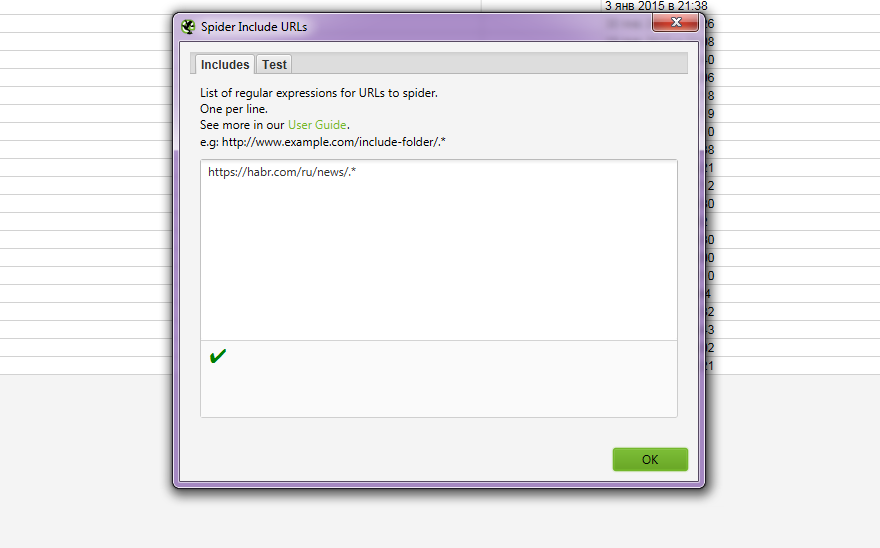
Для этого идём во вкладку configuration, раздел include. И там задаём нужную директорию следующим образом example.ru/blog/.*
У меня нет в работе больших блогов или новостников, поэтому я для статьи беру в пример старый добрый хабр, и вовсе не хочу парсить его весь.
В итоге мы получаем отдельную колонку с результатами, которые можно выгрузить, как и любой обычный аудит Screaming Frog. Если вам не нужен весь отчёт, то собранные данные можно скопировать во вкладке custom.
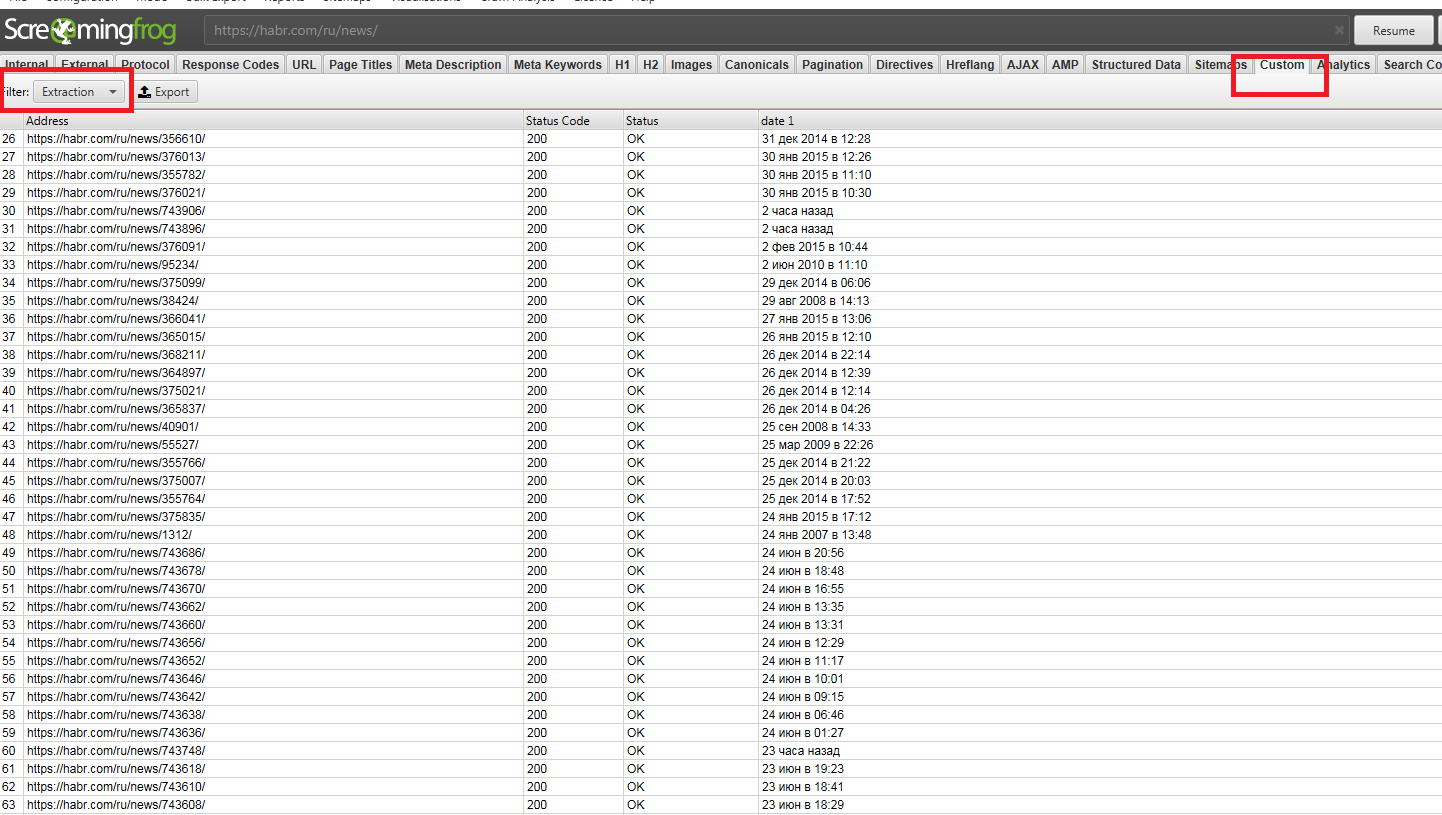
Данные конечно имеют вес сами по себе, но не лишним будет скомпоновать их в в гугл таблицах с колонкой word count (чтобы быстро найти также страницы где мало контента), а также с информацией о позициях и посещаемости этих страниц, которые можно взять из GSC. Так вам будет проще выставить приоритеты.
Как правильно обновлять контент
Очень важно после этих манипуляций правильно проработать контент. Поскольку многие знают, что его нужно обновлять, но под обновлением подразумевают исправление грамматических ошибок, и замену цен. Это не так. Но также ошибкой будет считать, что обновление контента, это новые блоки текста. И вообще, желательно не делать со страницей что-то одно.
- Новая релевантная информация по теме. Это конечно самое главное. Часто в GSC можно найти запросы по которым у страницы есть показы, но нет кликов. Там, порой на самой поверхности, лежат идеи для дополнительных блоков текста. Также естественно смотрим выдачу SERP - а что есть у них? Сюда же отнесём проработку LSI-семантики.
- Графический контент и таблицы. Часто самый простой способ вдохнуть новую жизнь в статью. Добавьте новых фото и видео. Если речь о коммерции, то наверняка можно притянуть к тексту ваши новые кейсы или что-то ещё из портфолио. В ряде случаев видео может быть не вашим, но несущим реальную дополнительную ценность читателю.
- Ссылки. Да-да перелинковка и простановка ссылок на источники цитирования - это также обновление контента. В том числе, нет ничего страшного во внешних ссылках на авторитетные сайты.
- Метаданные. В ряде случаев можно скорректировать title, h1, description на странице. Здесь уже всё зависит от наличия и отсутствия позиций у страницы в данный момент. Однозначно нельзя допускать привязки в метаданных (да и в самом контенте) к неактуальным датам “Лучшие лаки для паркета в 2020 году”.
- Смена url. Сюда же можно отнести смену url с последующим редиректом. Допустим, если туда опять же попала дата публикации в силу специфики вашей CMS. Либо адрес потерял релевантность по другой причине.
Для кого метод неактуален
- В первую очередь это применимо для страниц у которых есть или, как минимум был хороший трафик. Если вы изначально не попали в топ-10, то начинать нужно с более базовых манипуляций.
- Страница ранжируется год и более. Не имеет смысла пытаться бустить таким образом созданное пару месяцев назад.
- Очевидный совет, но не трогайте то, что и так прекрасно работает. Если страница в ТОП 3-5. то просто займите себя чем-то другим.
В остальном, периодическая работа по обновлению контента даёт вполне ощутимые результаты, причём довольно быстро. Это местами скучная, скрупулёзная работа, но оно того стоит. Успехов!

Успешно отправлено!


