Чистка ключевых запросов в Key Collector
Начиная работать с семантикой, создаётся впечатление, что главная трудность для SEO-специалиста – это её собрать. Я сам помню, как впервые запустив Key Collector был, мягко говоря, обескуражен и не совсем понимал, что делать дальше.
Однако, когда немного осваиваешься со сбором ключей, становится понятно, что сбор лишь верхушка айсберга, а вот чистка и кластеризация действительно съедают уйму времени.





Порядок действий
Несмотря на то, что с парсингом в Key Collector сейчас есть проблемы, работать с семантикой в программе по-прежнему очень удобно.
Немного отступив в сторону от темы чистки семантического ядра, хочу сказать, что собирать ключи всегда нужно из всех доступных источников. Мы в работе используем связку Key Collector + Keys.so + база Букварикс. Это позволяет охватить наибольшее количество семантики. Но, независимо от источника, затем все ключи отправляются в коллектор, поскольку дальнейшую чистку и группировку удобнее проводить именно там.
Внимание, господа. Чистка ключей – крайне ответственный процесс. С одной стороны, конечно, хочется делать это массово и быстро, с другой – одно неверное минус-слово и вы рискуете потерять важнейший кластер ключевых запросов. Поэтому действуйте спокойно и рассудительно.
На начальном этапе главная задача максимально быстро и безболезненно сократить количество фраз, чтобы в финале, когда мы перейдём к ручной чистке, процесс не растянулся на целую вечность.
Неявные дубли
Первое, что я делаю собрав ключи – это удаляю неявные дубли.
Вкладка данные → неявные дубли → умная отметка → удалить отмеченное.
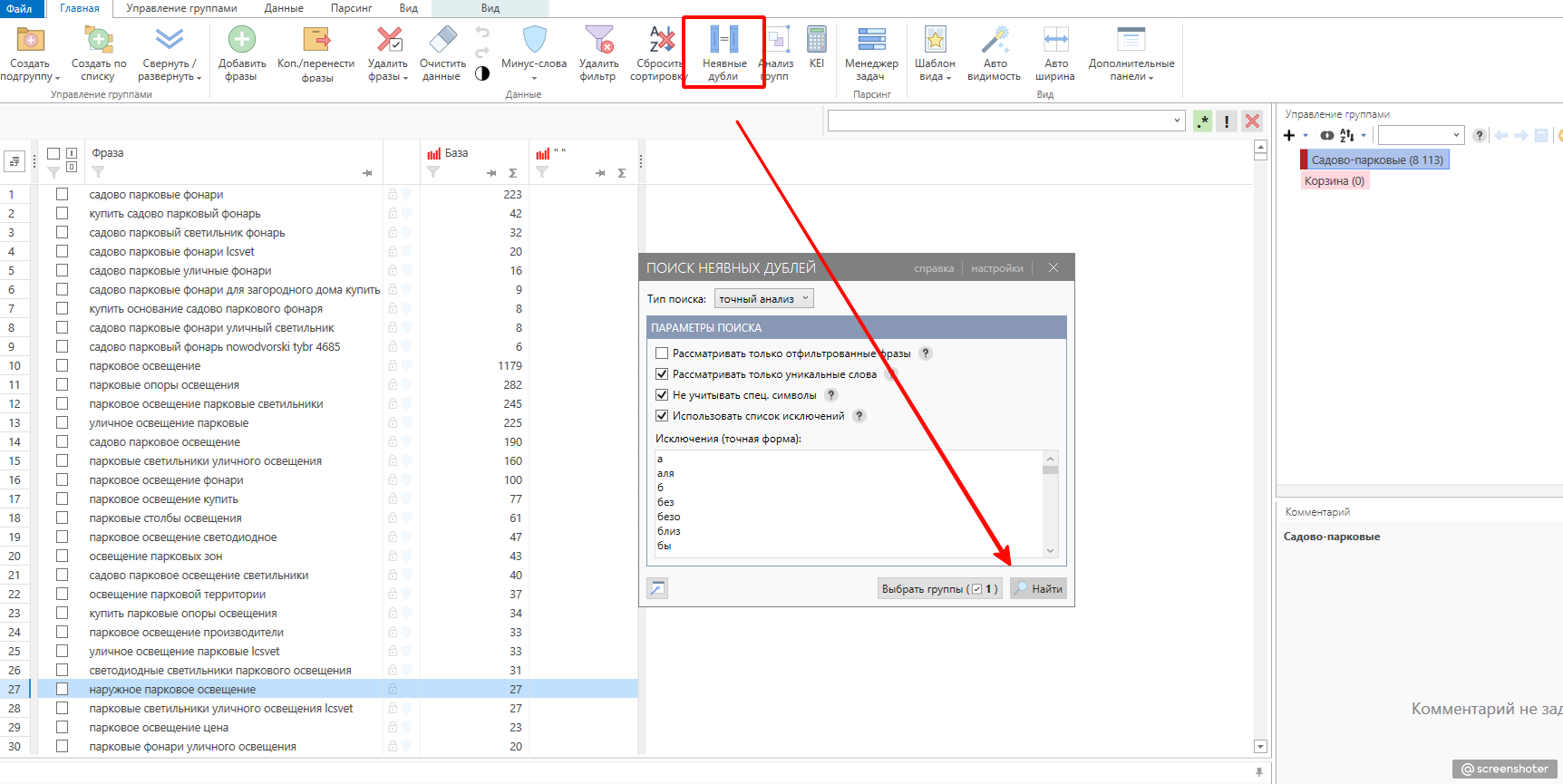
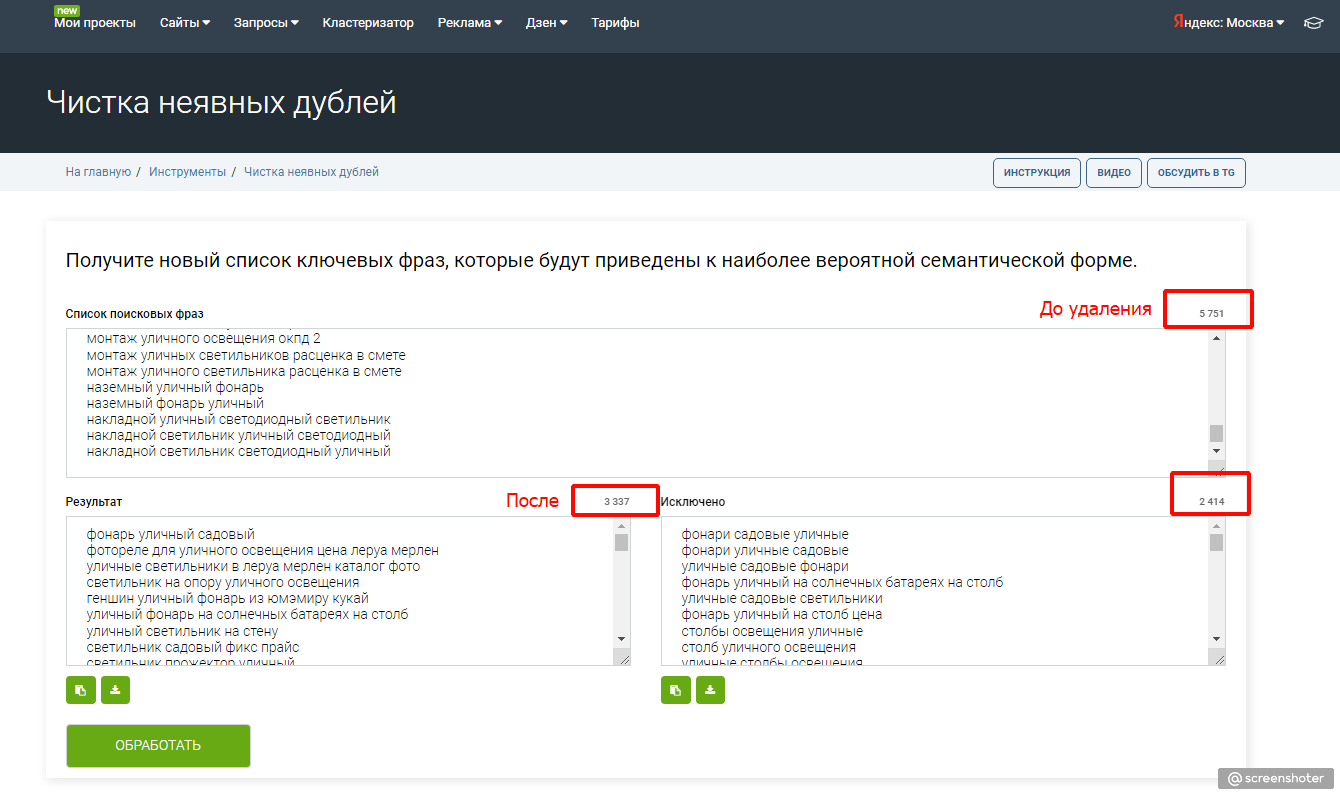
Особенно грешит неявными дублями и прочим мусором keys.so. Справедливости ради первичную чистку можно сделать, не выходя из него. Во вкладке “Запросы” есть инструмент для чистки неявных дублей. В моём примере из 5751 фразы осталось 3337.
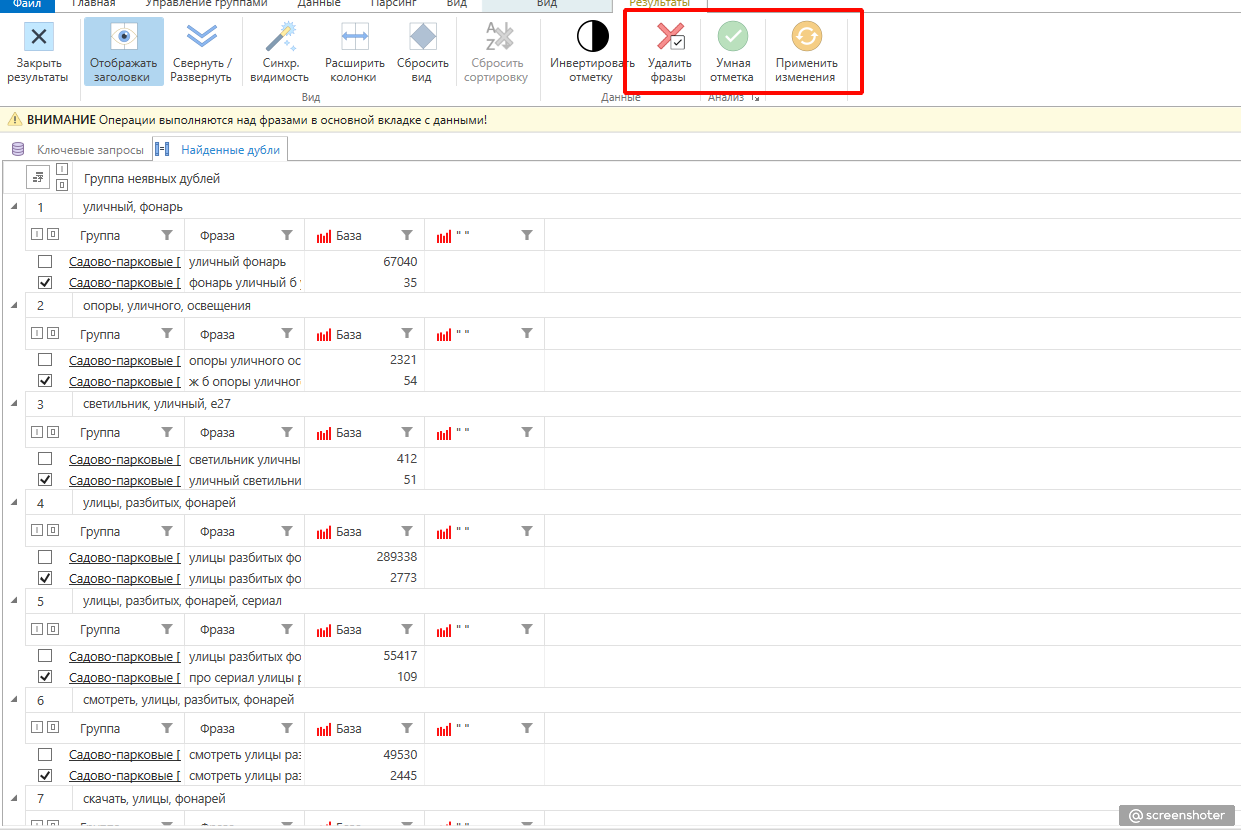
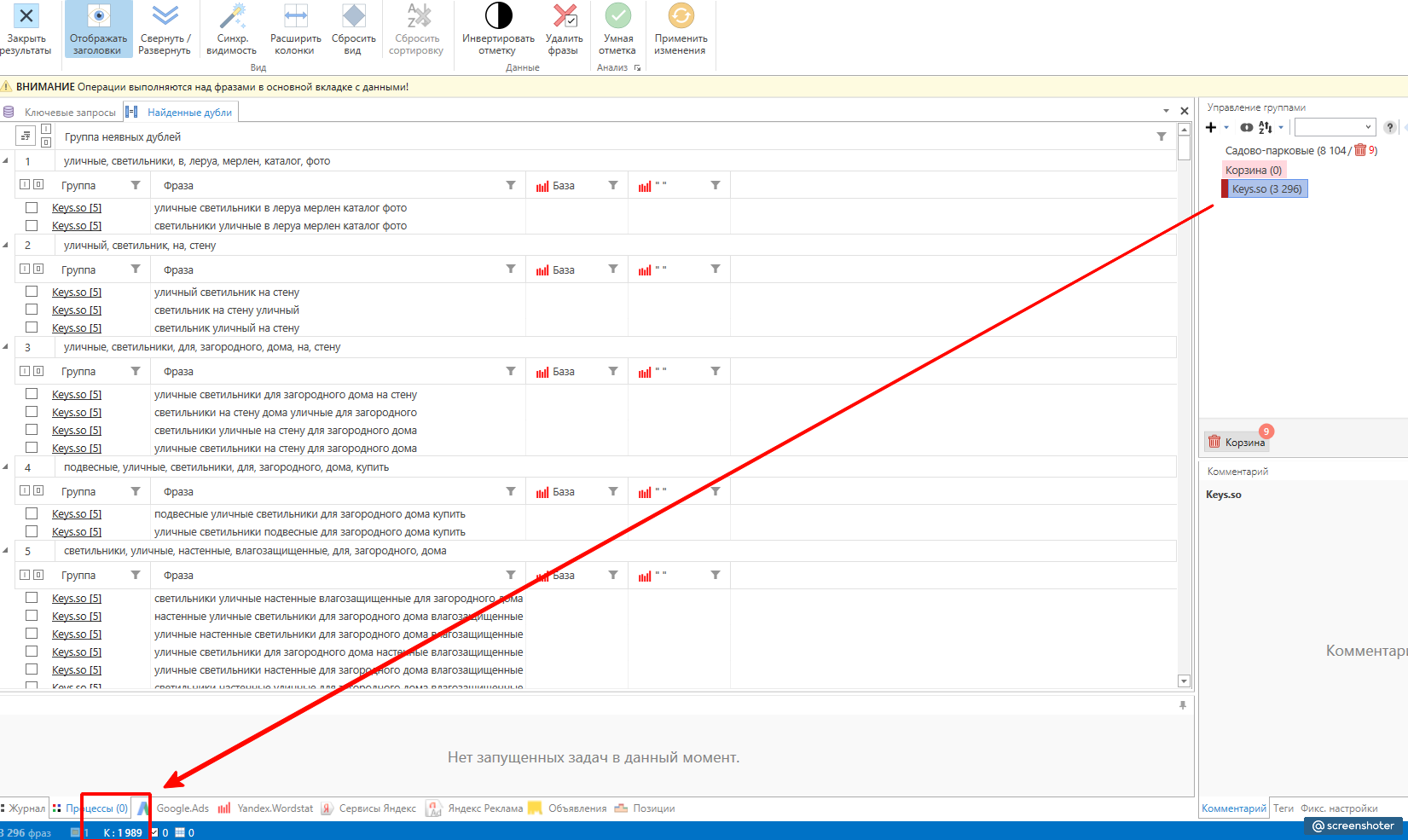
Копируем их и отправляем в Key Collector. Обычно я закидываю их в отдельную группу, и сразу ещё раз проверяю на неявные дубли. Обратите внимание, что нашлось ещё 1989 фраз.
Если после проверки в режиме “Точный анализ” вы всё равно видите значительное количество дублей, то перейдите на “Углубленный анализ”. В большинстве случаев я использую именно этот способ.
Поиск пересечений
Следующим шагом я удаляю фразы повторяющиеся в группах, а затем переношу запросы собранные в Keys.so в общую черновую группу.
Для этого используем инструмент перекрёстный поиск во вкладке данные. В моём случае в корзину улетело ещё 658 фраз.
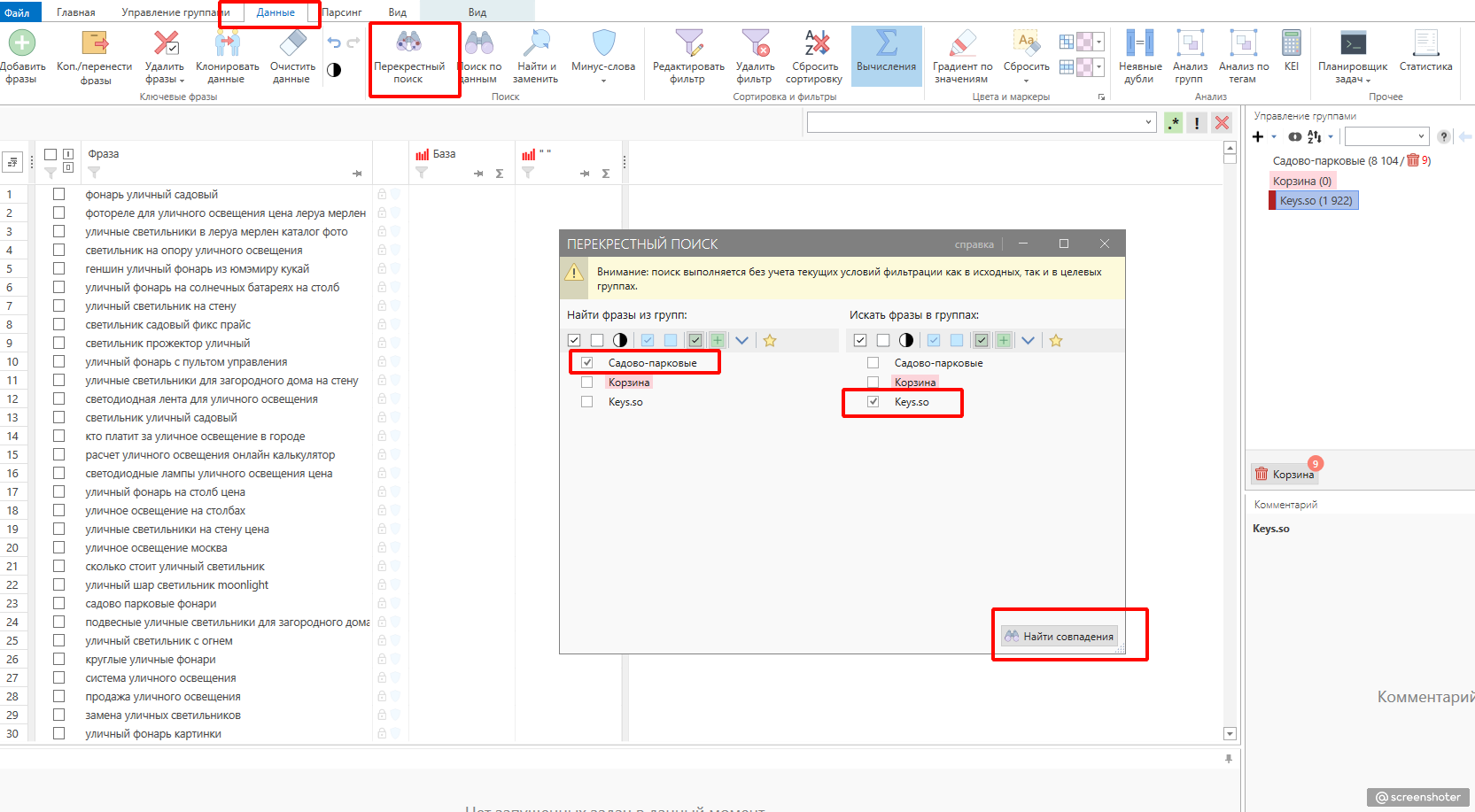
Аналогично поступаем с выгрузкой из Букварикс. Итого, спустя 15-20 минут у меня собрано и очищено от неявных дублей 10037 фраз для раздела “Садовое освещение”.
Чистка по критерию частотности
В плане удаления фраз, которые редко запрашивают нет универсального рецепта. Это будет сильно зависеть от ниши, региона, и специфики ключевых запросов. Естественно, работая с информационными ресурсами, или коммерческим сайтом подходы будут разные.
На следующем этапе собираем базовую и точную частоты за год по вашему региону. Создаём фильтр меньше или равно в колонке точной частотности . Я удаляю всё, что искали меньше 12 раз за год. В два клика сокращаем рабочий список до 5230 запросов. То есть буквально в два раза.
Удаление по спискам минус-слов
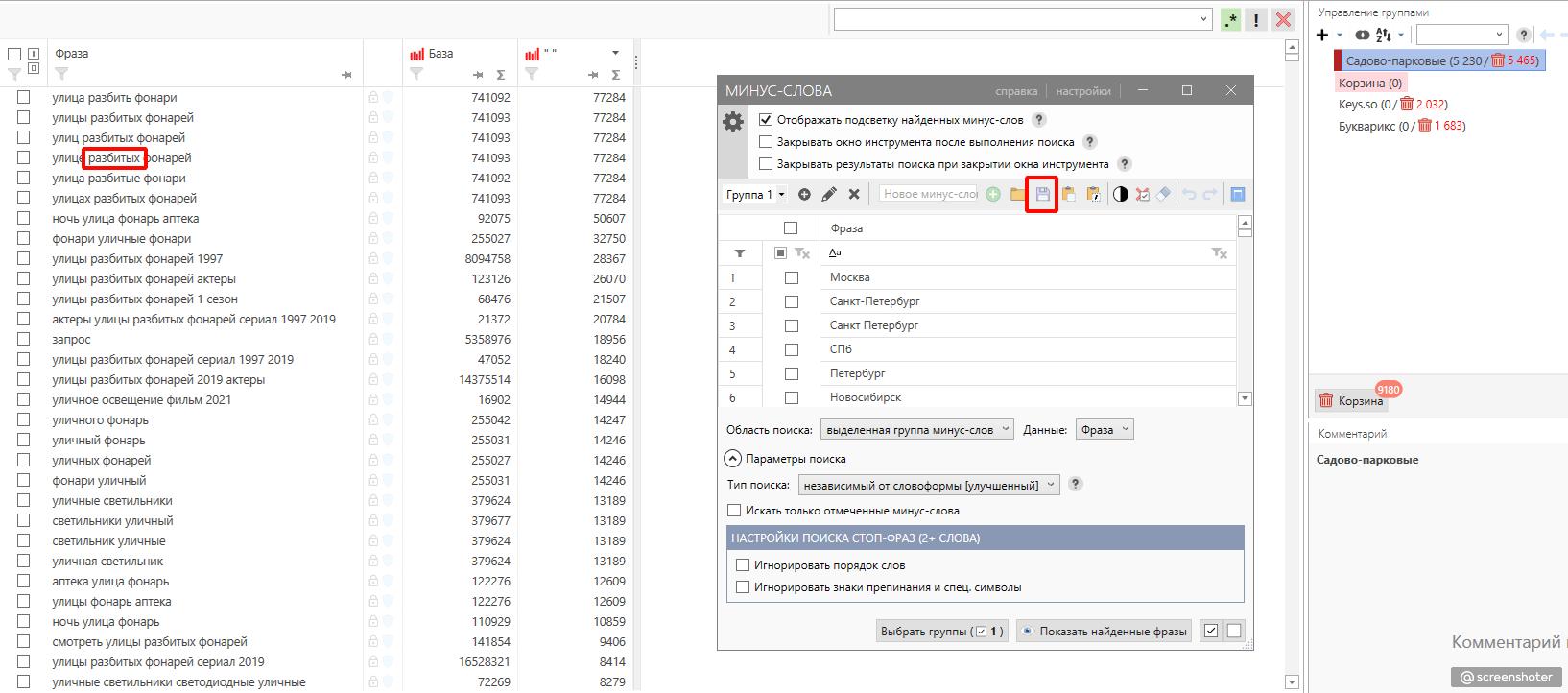
Далее чистим слова по спискам минус-слов (скачать их можно ниже). Естественно, готовых минус-фраз вам будет мало, и в процессе вы их будете пополнять.
У меня, например, затесался знакомый с детства сериал “Улицы разбитых фонарей”. Добавляем в стоп-лист “разбит*”. Вышло аж 909 нецелевых фраз. Туда же вписываем слово аптека, из бессмертного произведения Александра Блока.
Здесь мы приходим к этапу, на котором всё больше придётся делать руками. Терпеливо прокручиваем наши ключи, добавляя в список стоп-слов всё лишнее: бренды, нецелевые слова, числа, и так далее.
Чтобы не набирать каждое встретившееся слово в стоп-лист вручную, добавлять их туда можно прямиком из списка. Очень удобно и значительно ускоряет процесс.
Кликаем на небольшую иконку щита справа от основной колонки и выбираем в выпадающем меню опцию “разбить на слова”.
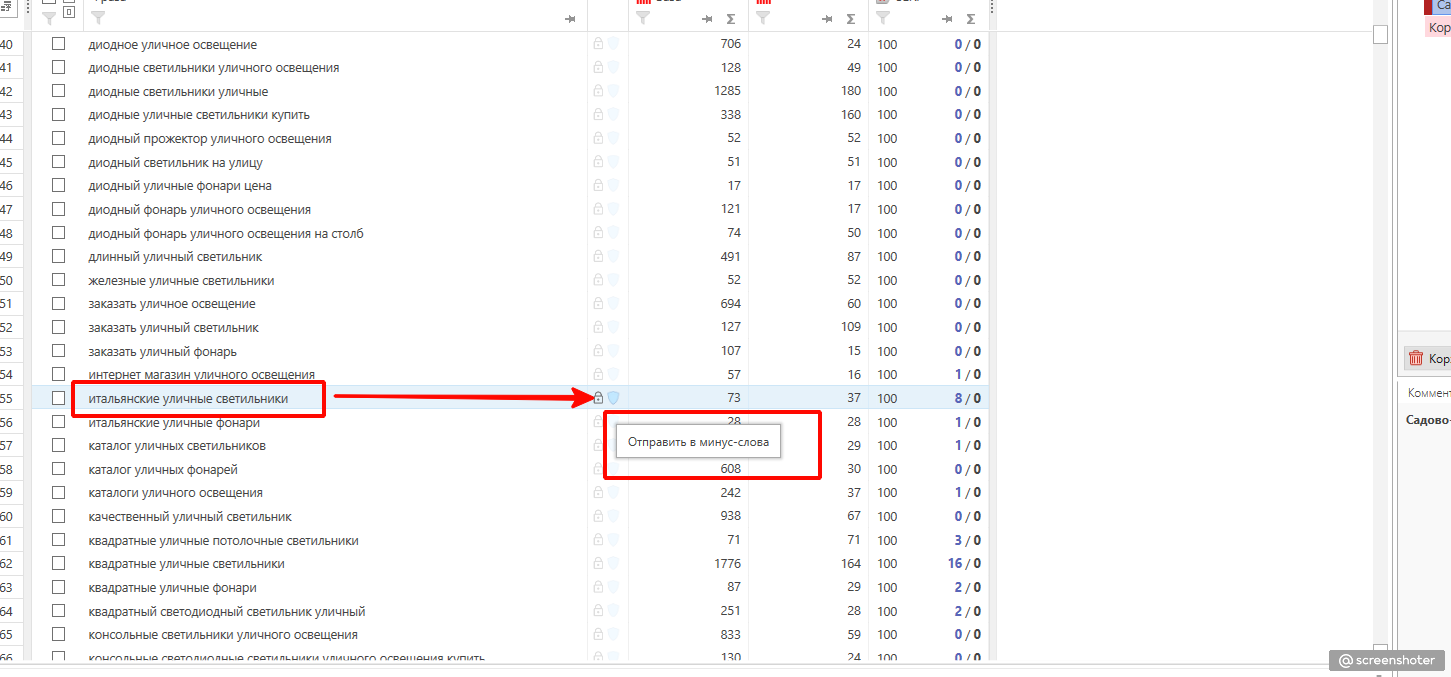
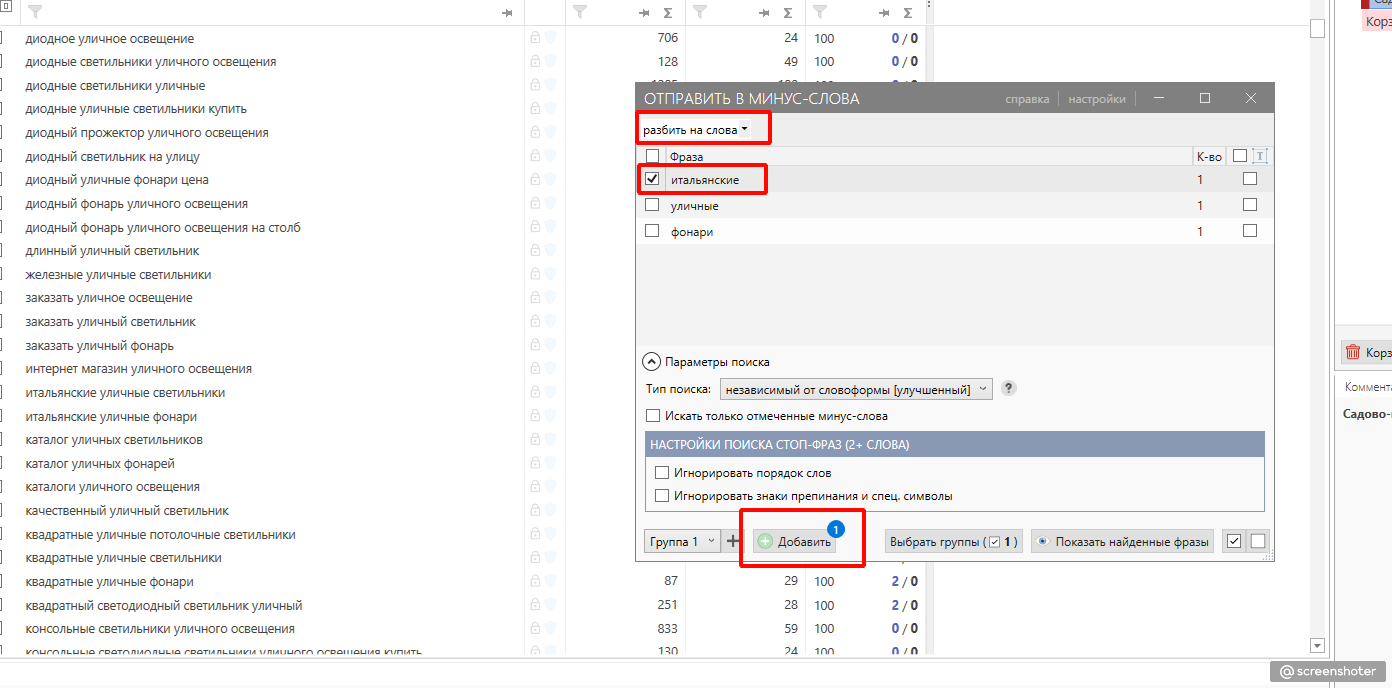
Отмечаем нужное слово, и оно пополняет наш текущий список для минусации.
Скачать списки стоп-слов для Key Collector
За годы SEO-продвижения сайтов, мы собрали из разных источников немало минус-слов, для чистки семантики в Key Collector или другом аналогичном софте или онлайн-сервисе. Вы можете найти их в нашем чек-листе (раздел “Работа с семантикой”) и сохранить куда-то к себе на будущее.
Список объёмный, но неплохо структурирован по смыслу и всё самое необходимое в нём присутствует:
- Города и страны
- Станции метро
- Обсценная лексика
- Adult запросы
- Универсальные минус-слова
- Многое другое
Можете скомбинировать свой идеальный список из нескольких, и постепенно пополнять. Чтобы не заниматься этим каждый раз заново, их лучше сохранить в текстовый файл. Однако, универсальный список на все случаи жизни создать в принципе невозможно.
Как сделать приятнее процесс дальнейшего рукоблудия?
Полностью избежать ручной чистки не выйдет, и в итоге именно ручной отбор съест значительную часть вашего времени.
Но есть несколько способов ускорить и упростить этот процесс. В этом нам помогут фильтры в колонке с фразами.
Убираем слишком широкие запросы
Логично, что слово “фонарь” охватывает все фонари в этом мире, в то время, как мне нужны только садово-парковые. Поэтому я сразу фильтрую все однословники, и в большинстве случаев, их все удаляю.
Далее также пробегаюсь по двухсловникам, там тоже часто встречаются общие понятия.
Чистим латиницу, цифры и многословники
Затем заходим с другого конца и фильтруем все фразы из 8 слов и более. Как правило, если вы работаете не с информационным сайтом, то там не будет ничего нужного.
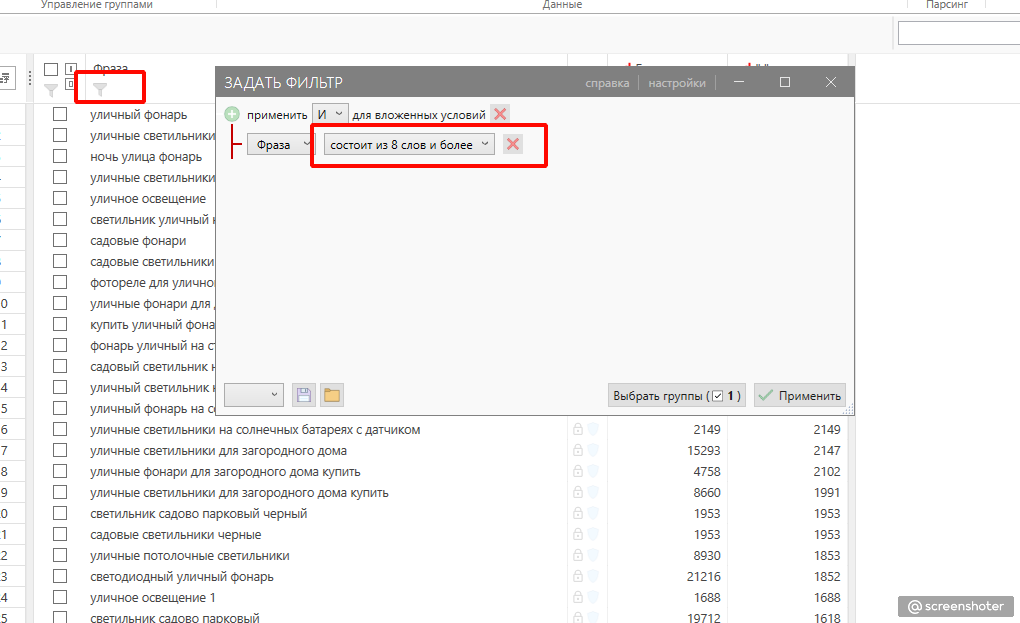
Ещё запросы можно прогонять через фильтры “содержат латиницу”, “латиница + цифры”, “содержит цифры”. В большинстве случаев вы там найдёте массу запросов на конкурирующие бренды, артикулы, названия моделей, маркетплейсов и тому подобное.
Ручная чистка
Переходя к ручной чистке оставшихся 2К+ запросов, я фильтрую фразы в алфавитном порядке и методично прокручиваю весь список, вновь дополняя свой перечень минус слов. Упорядочив запросы по алфавиту, мы как-бы предварительно “группируем” ключевые слова и, в том числе, сразу отлавливаем большие кластеры мусора.
Безусловно, ручная очистка семантического ядра наиболее трудоёмкий и длительный этап. Требуется особый склад ума и усидчивость, чтобы делать это качественно. Тем важнее максимально быстро и продуктивно очистить ядро на начальном этапе, чтобы свести финальную рутину к минимуму.
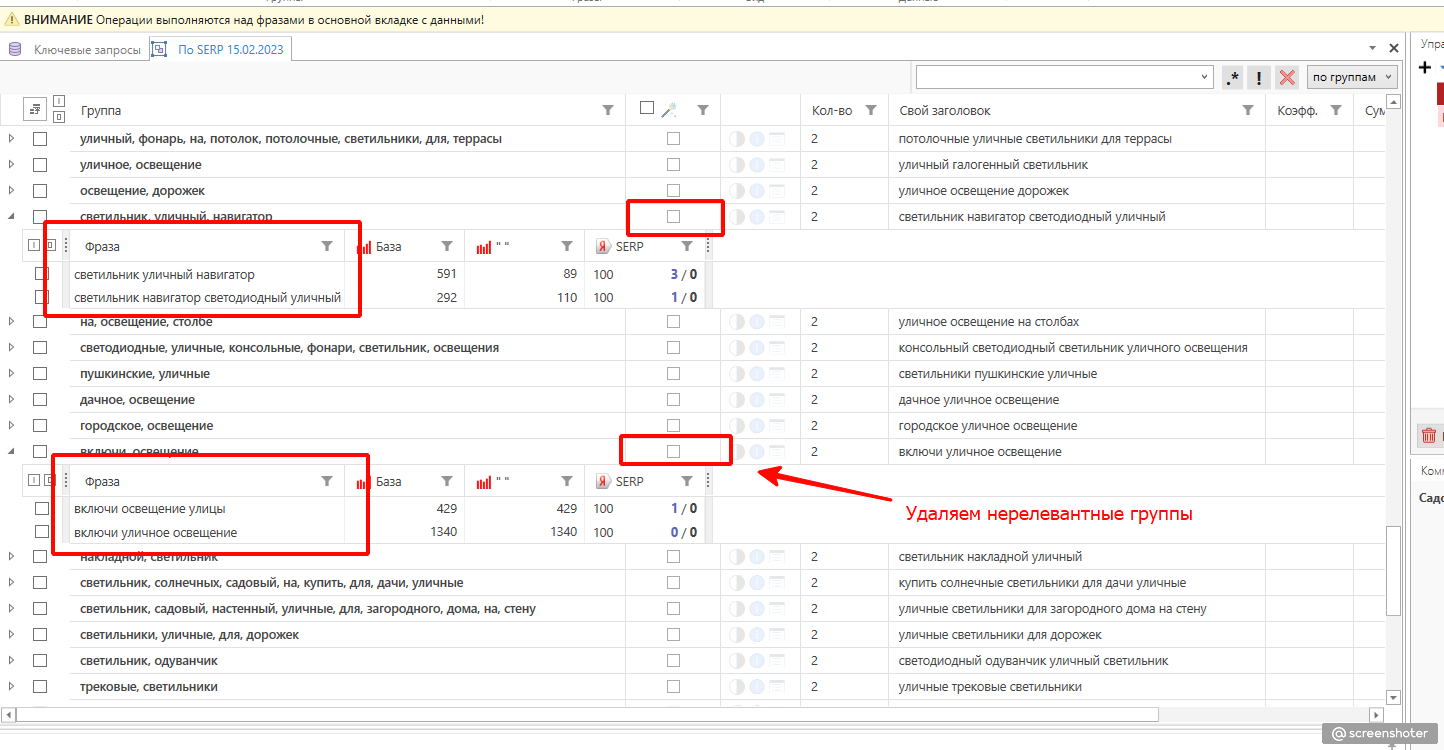
Пройдясь ещё раз по списку руками, я оставил 909 слов. Напомню, что изначально было 10К+. На этом шаге мы переходим к кластеризации запросов.
После кластеризации (в моём случае я группирую по топ-10 Яндекс) мы ещё раз вручную проходим по всем запросам, наводя окончательный лоск в семантике. Но делать это теперь немного проще, поскольку перед нами целые кластеры нерелевантных запросов, упущенных на прошлых этапах. Плюс мы уже можем бегло оценить количество посадочных и необходимый нам объём ключей для этих страниц.
Заключение
Процесс очистки семантического ядра один из самых фундаментальных в SEO-продвижении вообще. Удалили лишнее - потеряли трафик. Оставили ненужное - тратим бюджеты клиента, свои время силы и нервы.
Помимо владения инструментами, важно глубоко проникнуть в специфику бизнеса и адекватно оценивать свои силы, конкуренцию кластера и целесообразность создания посадочных. Это кропотливый и местами нудный процесс, но без него не обойтись. Тем важнее уметь отсечь основную массу ненужного программно, чтобы на завершающем этапе тратить в разы меньше времени на чистку и кластеризацию. Успехов!

Успешно отправлено!



