Сбор ключевых слов и назначение посадочных страниц
Первым шагом к продвижению сайта является продуманное семантическое ядро.
Семантическое ядро сайта (далее СЯ) – это сформированный список поисковых запросов пользователей, по которым планируется продвижение нашего сайта.





Сбор маркерных запросов
Маркерные запросы – это запросы, которые четко отвечают продвигаемой странице. В большинстве случаев маркерным запросам соответствуют названия разделов, категорий, рубрик на сайте. Маркерные запросы нужны для того, чтобы в дальнейшем на их основе найти ключевые слова.
Например, на сайте имеется раздел «Циклевка паркета» - это наш маркер, с помощью которого формируются ключевые запросы, а именно: «циклевка паркета спб», «циклевка паркета спб недорого», «циклевка паркета цена» и т.д.
Маркерные запросы являются базовыми запросами по которым в дальнейшем будут собраны остальные ключевые запросы в автоматическом режиме. Поэтому, если упустить какой-то маркерный запрос, есть риск потерять значительный пласт ключевых запросов.
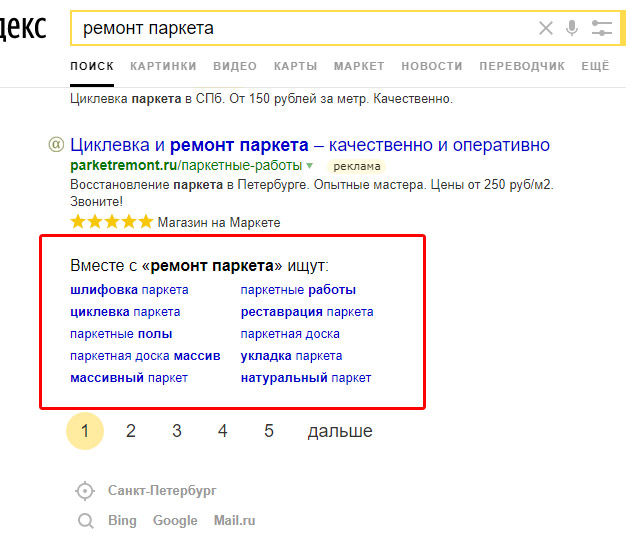
Одним из методов подбора маркерных запросов являются поисковые подсказки Яндекс. С их помощью можно найти другие часто задаваемые поисковые запросы. Как видно из рисунка ниже, при введении в поиск Яндекса ключевого запроса «ремонт паркета», получаем подсказки: «циклевка паркета», «шлифовка паркета», «укладка паркета» и др.
Вторым методом подбора маркерных запросов, является сервис wordstat.yandex.ru. При подборе запросов данным методом, удобно использовать Yandex Wordstat Assistant – это расширение для браузеров Google Chrome, Яндекс.Браузер и Opera. Перед началом поиска запросов нужно уточнить регион сбора данных. Далее, в строку поиска вводим маркерный запрос. В случае если какой-либо подобранный запрос из правой или левой колонки результатов подходит, нажимаем на иконку «+» напротив запроса, таким образом формируя полный список маркерных запросов.
Парсинг ключевых слов в программе Key Collector
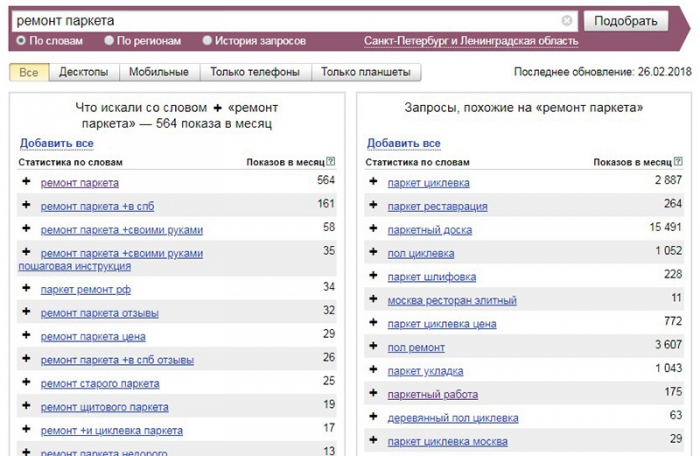
Для составления СЯ по запросам ПС Яндекс, используем программу Key Collector. Она позволит провести пакетный сбор всех ключевых запросов на базе наших маркеров, которые интересны для продвижения сайта, а также соответствующие им базовые частотности из сервиса wordstat.yandex.ru.
Базовая частотность (далее БЧ) – прогнозируемое количество показов введенной фразы в месяц с любыми другими словами, в любом склонении, падеже и числе. Например, если ввести «ремонт паркета», мы получим количество показов в месяц таких запросов, как «ремонт паркета в спб», «ремонт паркета недорого», «ремонт паркета цены» и т.д.
Точная частотность «” ”» (далее ТЧ) - прогнозируемое количество запросов в месяц введенной фразы без каких-либо других слов, но в любом падеже, склонении, числе. Например, если ввести «”стоимость паркета”», мы получим следующие запросы: «”паркет стоимость”», «”стоимость паркет”».
Также возможен сбор поисковых подсказок, который можно провести сразу после парсинга списка ключевых слов из левой колонки Yandex.Wordstat. Рекомендуется собирать поисковые подсказки после фильтрации полученного списка запросов и удаления всех лишних фраз. Таким образом, сбор поисковых подсказок будет производится из большего количества ключевых запросов, что позволит увеличить список дополнительных подсказок с ПС Яндекс.
Как собирать поисковые подсказки описано после способов фильтрации.
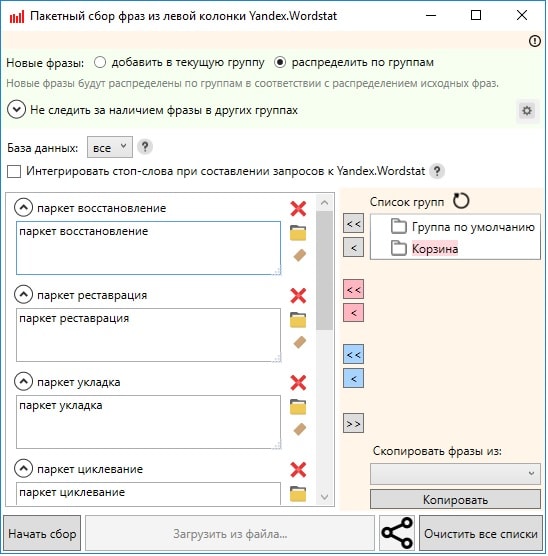
В начале работы создается новый проект. Для этого заходим во вкладку «Файл» и выбираем пункт «Новый проект». Далее, чтобы более точно оценить полезность того или иного запроса, необходимо обозначить интересующий регион. Так как настройки региональности для Яндекс.Директ и Яндекс.Вордстат независимы, устанавливаем регион во всех пунктах.

Нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat». Затем, копируем ранее полученный список ключевых фраз из расширения для браузера Yandex Wordstat Assistant и вписываем остальные ключевые фразы, если таковые имеются. Для последующего упрощения процесса фильтрации, список запросов можно разделить на группы. Чтобы запустить процесс, нажимаем кнопку «Начать сбор».
Программа собирает статистику в классическом режиме, который установлен по умолчанию, при этом, в результате, для каждой фразы получаем данные по показателю базовой частотности.
После завершения процесса рекомендуется удалить все запросы с БЧ равной или ниже 5, так как данные запросы, скорее всего, являются мало запрашиваемыми и не принесут желаемого трафика.
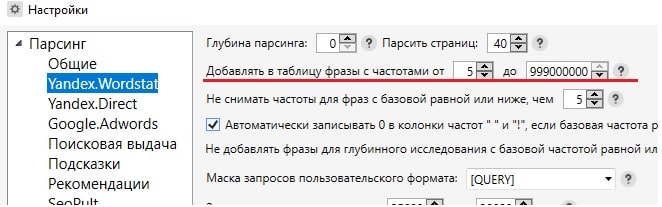
Данной процедуры можно избежать, если в начале работы, в иконке «Настройки», перейти во вкладку Yandex.Wordstat и там, в строке «Добавлять в таблицу фразы с частотами от до», выставить необходимое число.
Сбор частотностей
Теперь собираем статистику через Yandex.Direct. В данном режиме программа совершает скоростной съем точной частотности для каждого оставшегося запроса.
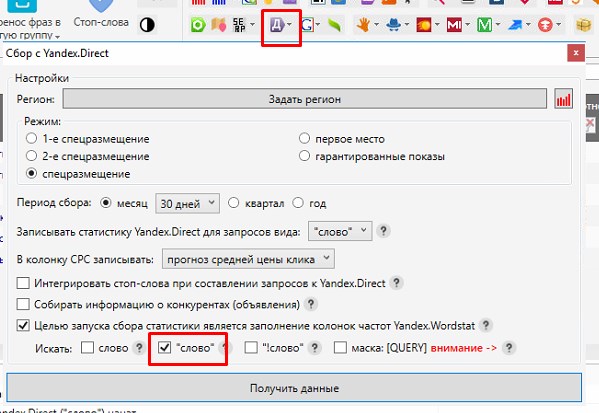
Для того чтобы быстро отфильтровать все запросы с ТЧ ниже 5, в колонке «Частотность “ ” [YW]» кликаем на значок «Редактировать условия фильтрации». В появившемся окне выпадающего меню выбираем пункт «Меньше» и указываем нужное значение. Нажимаем «Применить». Получаем список всех запросов с ТЧ меньше 5.
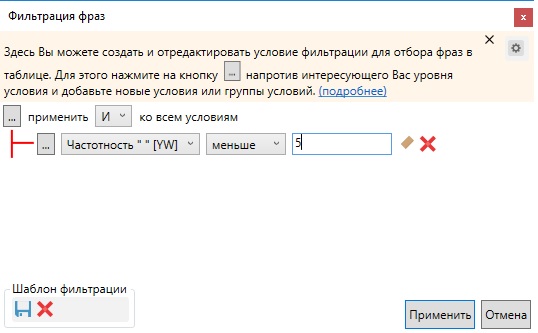
Данные запросы выделяем галочкой, нажимаем правую кнопку мышки и выбираем пункт «Удалить отмеченные строки».
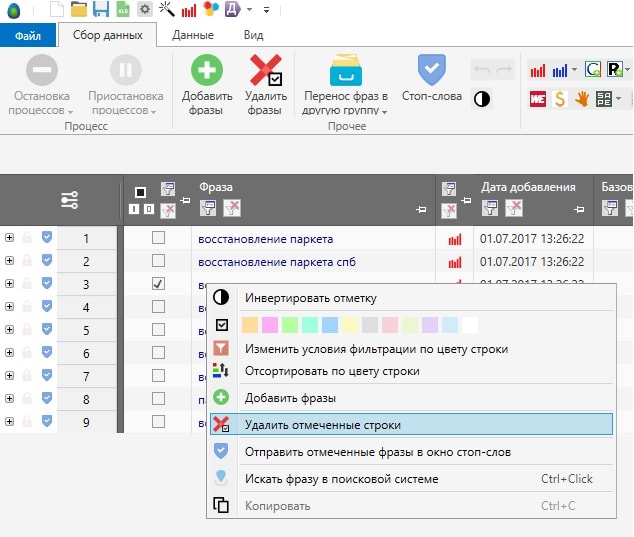
Для того, чтобы отобразились остальные фразы с ТЧ больше 5, нужно в колонке "Частотность " "" кликнуть на значок «Удалить колонку из текущих условий фильтрации». В итоге, мы получаем все оставшиеся фразы, ТЧ которых больше 5.
Фильтрация полученных ключевых фраз
Используя данные методы можно быстро почистить список полученных ключевых запросов от нецелевых.
Составление списка стоп-слов
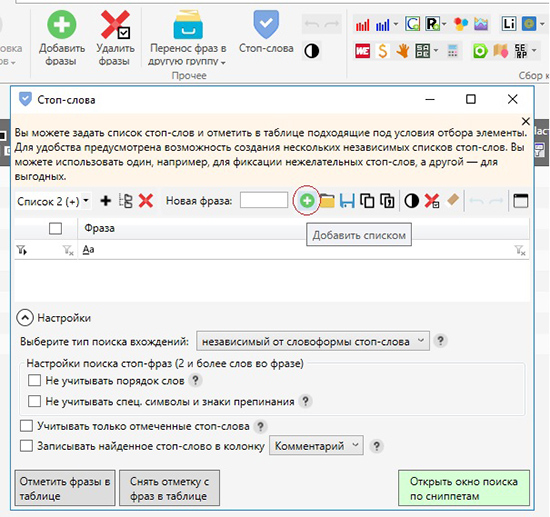
Если при просмотре списка запросов встречается слово, которое не подходит, нужно кликнуть на иконку «Стоп-слова» слева от запроса. Далее, в появившемся окне, отметить слово галочкой и нажать «Добавить в стоп-слова». В результате, все фразы в списке, которые содержат данное слово, будут отмечены галочками и их можно будет легко удалить.
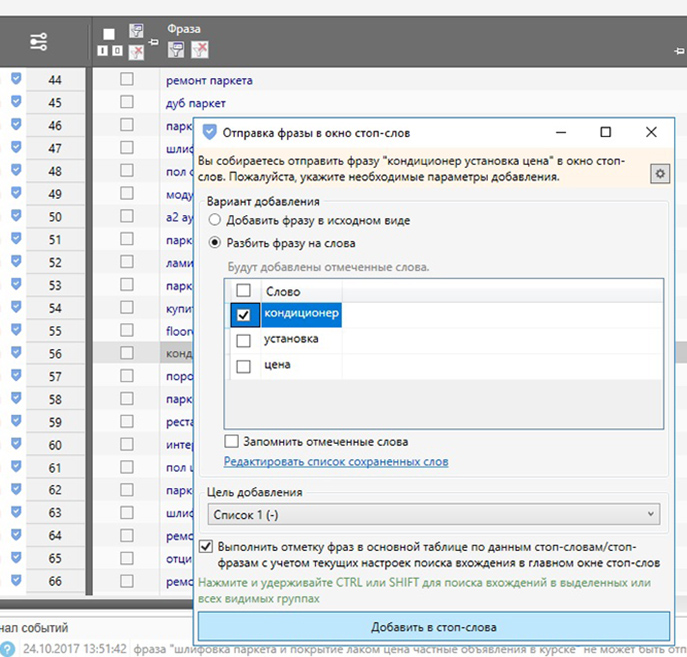
В случае, если имеется уже готовый список стоп-слов, во вкладке «Сбор данных» нужно выбрать пункт «Стоп-слова». В появившемся окне нажать опцию «Добавить списком» или «Загрузить из файла». Отметить галочками нужные стоп-слова, нажать «ОК» и кликнуть на иконку «Отметить фразы в таблице». Если отмеченные фразы действительно являются лишними, их можно удалять.
Функция регулярных выражений
В колонке «Фраза» нужно кликнуть на иконку «Редактировать условия фильтрации» и выбрать опцию «удовлетворяет рег. выражению» и вставить в поле какое-либо регулярное выражение.
Например, для того чтобы выбрать все фразы, содержащие цифры, используется следующее выражение - «\d+». А для того, чтобы обозначить все запросы, которые представляют собой вопросы, в строку вписываем «^как». Тогда получится список фраз, которые начинаются со слова «как», а также «какой», «какая», «какие». В случае использования выражения «бесплатно$», получим все запросы, которые заканчиваются на слово «бесплатно».
Существует ряд других регулярных выражений, которые могут быть полезны и позволят существенно сэкономить время фильтрации списка запросов:
| Регулярное выражение | Обозначение |
| \d+ | выбрать все фразы, содержащие цифры |
| ^скачать | выбрать все фразы, начинающиеся со слова "скачать" |
| скачать$ | выбрать все фразы, заканчивающиеся на слово "скачать" |
| скачать | выбрать все фразы, содержащие слово "скачать" |
| скачать|купить|продать | выбрать все фразы, содержащие любое из слов: "скачать", "купить" или "продать" |
| ^пластиковые(.)*цены$ | выбрать все фразы, начинающиеся на "пластиковые" и заканчивающиеся на "цены" (.)* - в регулярном выражении означает последовательность символов любой длины |
| ^(\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 2 слова |
| ^(\S+?\s\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 3 слова |
| ^(\S+?\s\S+?\s\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 4 слова |
| ^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 5 слов |
Анализ неявных дублей
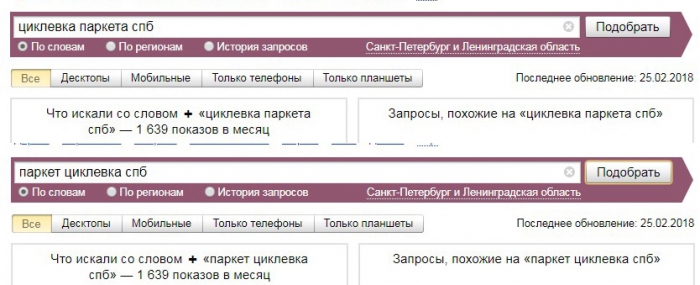
Неявные дубли представляют собой запросы, в которых одинаковые слова расположены в разном порядке. Например: «циклевка паркета спб» и «паркет циклевка спб».
Вводя в строку Яндекс.Вордстат данные запросы, получаем одинаковые или очень близкие значения ТЧ.
При использовании операторов Яндекс.Директ можно посмотреть точные вхождения данных запросов, и станет понятно, как именно набирают запрос пользователи. Тогда ТЧ данных двух запросов будут сильно отличаться, например, если поставить « [ ] » зафиксируется порядок ввода слов в запросе:
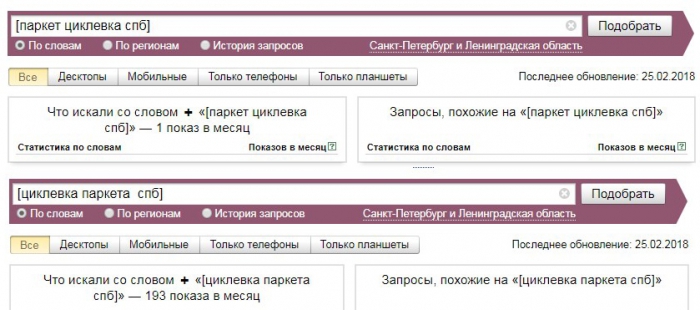
Если к запросу [циклевка паркет спб] добавить оператор « ! » , тогда зафиксируется словоформа и можно будет увидеть совсем другую картину:
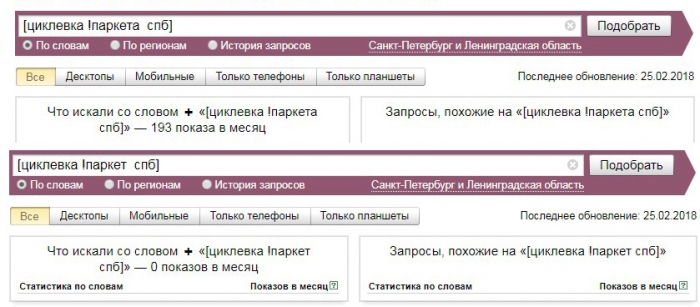
Во вкладке «Данные» нужно выбрать пункт «Анализ неявных дублей». В пункте «Параметры умной группировки» выбрать «Отметить все кроме самых высокочастотных в каждой группе». Затем нажать «Умная отметка». Те запросы, точная частотность которых ниже, отмечаются программой автоматически и их можно удалить.
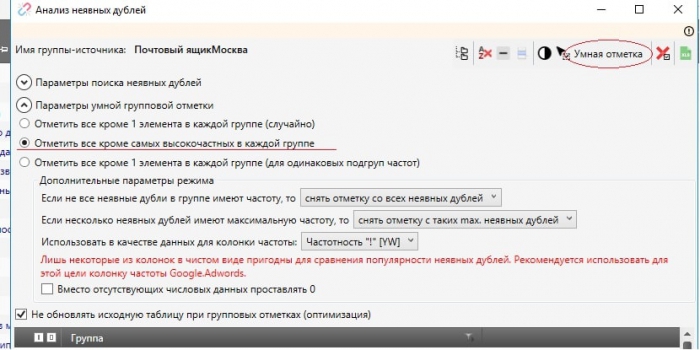
Быстрый фильтр
Быстрый фильтр удобен тем, что если ввести в строку слово или часть слова, например «паркет» и нажать Enter, получится список всех возможных словоформ введенного слова: «паркетный», «паркета», «паркетной».

Сбор поисковых подсказок
Сбор поисковых подсказок нужен для того, чтобы расширить список ключевых запросов, и является очень полезным инструментом, так как при парсинге Яндекс.Вордстат пропускаются фразы содержащие количество слов больше 7. Часто такие фразы представляют собой популярные информационные запросы, которые могут служить дополнительным источником трафика.
В начале работы в настройках нужно установить время ожидания между запросами, которые отправляет программа к поисковым системам при получении поисковых подсказок. Существует опасность блокирования IP-адреса из-за слишком большого количества обращений при парсинге подсказок, поэтому лучше в настройках установить длительный разрыв между запросами от ... до ... мс.
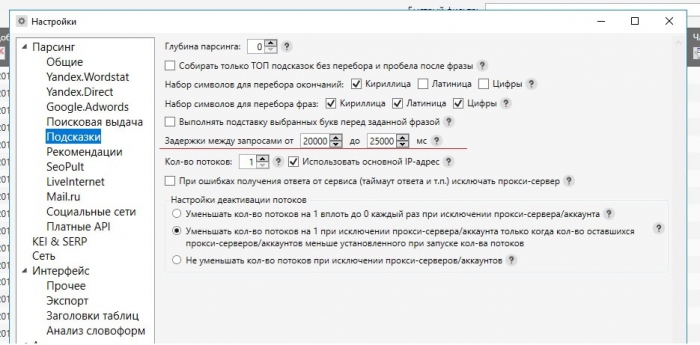
Для того, чтобы собрать подсказки, нужно нажать на кнопку с иконкой трех разноцветных сот в группе кнопок «Сбор ключевых слов и статистики».

Затем поставить галочку напротив ПС. И запустить процесс сбора подсказок. После окончания процесса провести фильтрацию списка ключевых запросов, описанными способами выше и экспортировать оставшиеся ключевые фразы в файл для работы с Excel.
Составление семантического ядра по запросам поисковой системы Google
Действия по составлению семантического ядра такие же, как и для Яндекса. Для начала необходимо определиться с маркерными запросами. Для этого можно также использовать Wordstat Yandex и поисковые подсказки Google. Для парсинга запросов используется программа Key Collector или сервис Keyword Planner (Планировщик ключевых слов) от Google Adwords. В результате получается список ключевых фраз, но данные по количеству запросов будут усредненными, так как Гугл не дает точных цифр. Более того, в неактивных кампаниях будут представлены только диапазоны значений.
Есть способ, который позволит более точно провести оценку запросов.
Фильтруем полученный список КС, убирая все лишние, нецелевые запросы. Затем в Планировщике ключевых слов заходим во вкладку «Получение статистики запросов и трендов».
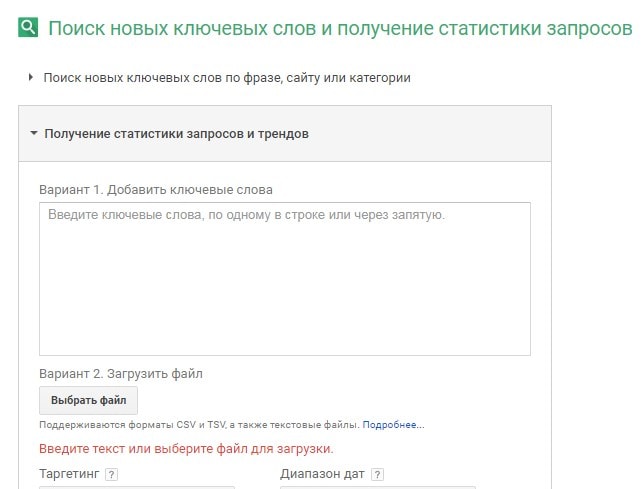
Вводим отфильтрованный список запросов и нажимаем «Узнать количество запросов». Затем нажимаем «Добавить все» и переходим в «План».
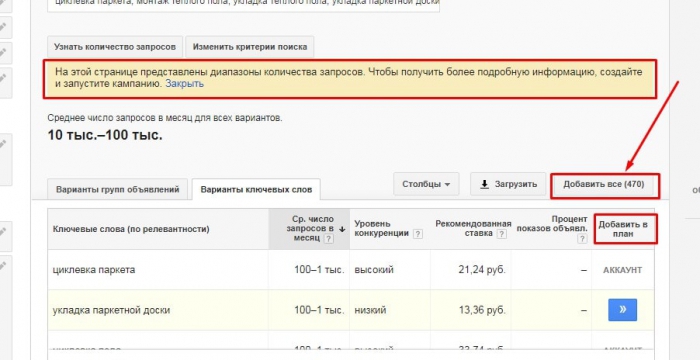
Теперь нужно задать очень высокую ставку и в «Прогноз за период» выбрать прогноз на месяц.
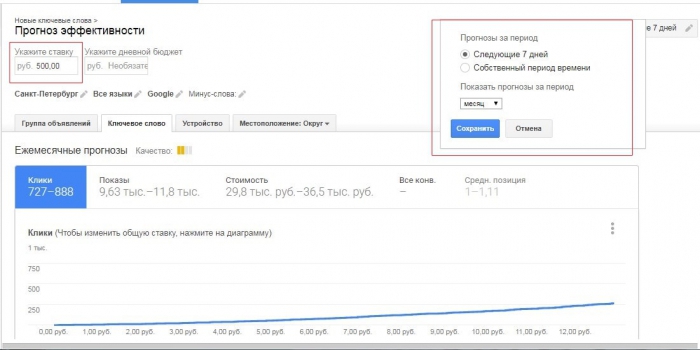
Во вкладке «Ключевые слова» загрузится таблица со значениями показов. По умолчанию отображаться будут показы для широкого соответствия.
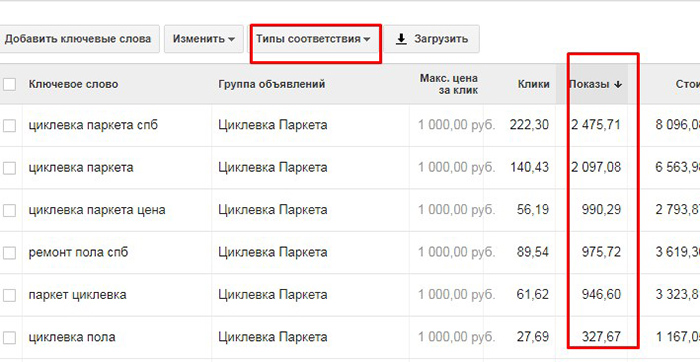
Для того, чтобы появились значения точного соответствия, нужно во вкладке «Тип соответствия» выбрать «Точное соответствие».
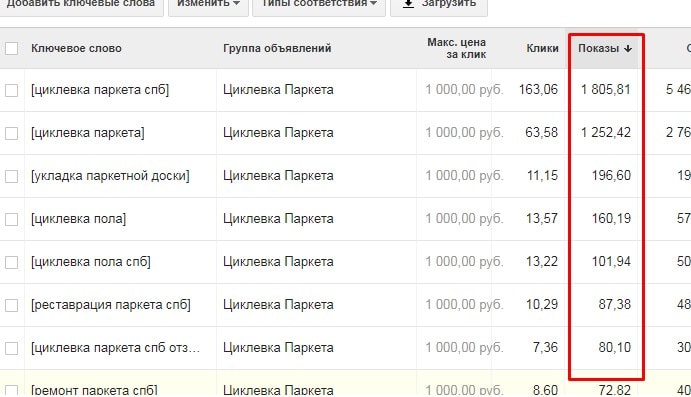
Для дальнейшей работы в Excel, нужно сохранить оба вида статистики в формате .csv файла. И там уже узнать эффективность запроса, поделив значения широкого соответствия на точное.
Группировка запросов
После фильтрации запросов нужно посчитать для них отношение БЧ к ТЧ и распределить по смысловым группам.
Отношение базовой частотности к точной показывает насколько эффективным является поисковый запрос. Если значение отношения БЧ к ТЧ большое, скорее всего запрос «пустой» и не стоит его использовать при продвижении страницы сайта.
Процесс группировки запросов занимает большое количество времени, чтобы сократить его, используется приложение «Подбор и кластеризация запросов» от Megaindex. Все что нужно сделать, это ввести доменное имя целевого сайта, добавить свой список запросов и запустить процесс кластеризации. Через некоторое время получается файл с разгруппированными запросами, которые нужно сопоставить с исходным файлом запросов, в котором есть значения частотностей и отношение БЧ к ТЧ. В данном случае пригодится функция ВПР для Excel. Функция позволит найти и перенести искомые значения частотностей из столбцов общего списка запросов в столбцы списка разгруппированных запросов.
Вводим формулу в первую ячейку столбца базовых частотностей:
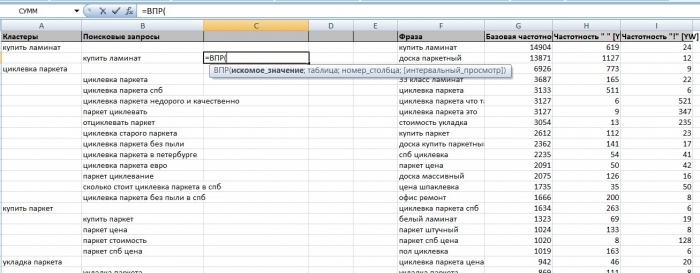
- искомое значение – нужно выделить первую фразу в столбце кластеризованных запросов;
- таблица – выделить таблицу общего списка запросов;
- номер столбца – ввести номер столбца (например, столбец с базовой частотностью второй);
- интервальный просмотр – поставить 0.
Затем нужно протянуть значения вниз, предварительно поставив знаки доллара у выделенного интервала таблицы.
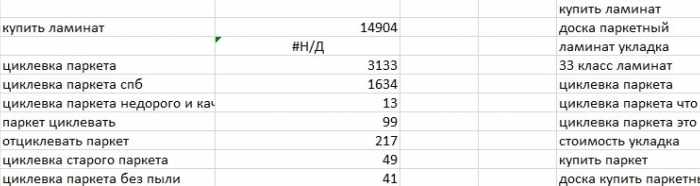
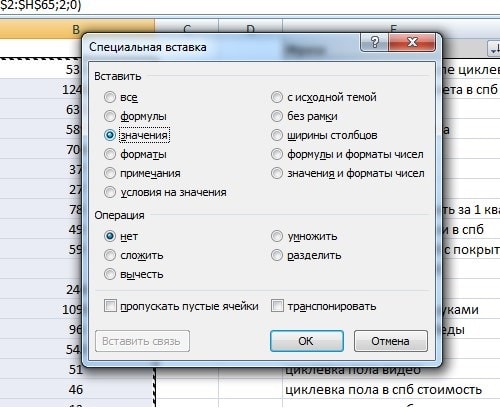
После того, как все столбцы со значениями будут перенесены, их нужно выделить и нажать копировать. Затем, нажав правую кнопку мышки, выбрать пункт «Специальная вставка» и там выбрать вариант для вставки «значения».
Таким образом перенесенные значения больше не будут ссылаться на искомые и их можно будет удалить.
Когда запросы разбиты на группы, нужно отнести наиболее запрашиваемые в группу «А», а все остальные в группу «Б». Данные запросы будут продвигаться в первую очередь.
Теперь запросам группы «А» назначаются посадочные страницы.
Есть правило - один КС должен соответствовать одной посадочной странице. В одной группе может быть несколько запросов, которые содержат дополнительные слова или похожи между собой и отображают какую-то одну суть.
Например: «циклевка паркета в спб», «циклевка паркета в спб недорого цены», «циклевка пола», «циклевка пола цены спб».
Эти запросы относятся к одной посадочной странице, которая должна быть оптимизирована именно под них и должна быть релевантной, т.е. в полной мере давать ответ на запрос пользователя. Если пользователь не найдет для себя нужной информации и сразу покинет страницу, это будет плохим сигналом для ПС и может плохо повлиять на дальнейшее продвижение сайта.

Успешно отправлено!


